Hey everyone, have abit of a strange one this time. About 2 months ago i was patching my Azure Stack HCI test cluster with the July patches and using Cluster Aware Updating via WAC. It went trough fine and the vm’s was up and all good. Nothing indicating any issues.
Then i went into WAC and i have degraded status, and i had an issue with some of my physical disks on 1 node. In powershell running get-physicaldisk it was showing this.
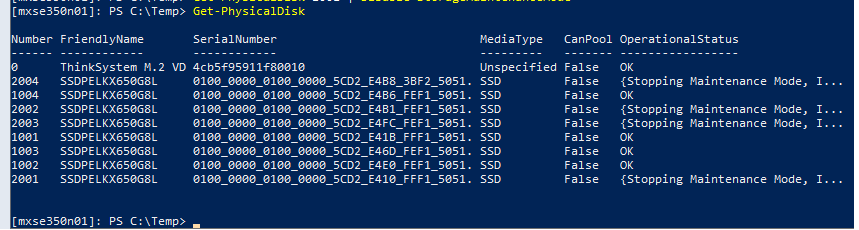
The disks where stuck in Stopping Maintenance Mode.
I tried a few things like disabling and enabling storage maintenance mode. But it did not work.

But it would fail with the error Invoke-CimMethod : Currently unsafe to perform the operation
Also tried Repair-ClusterS2D -DisableStorageMaintenancemode
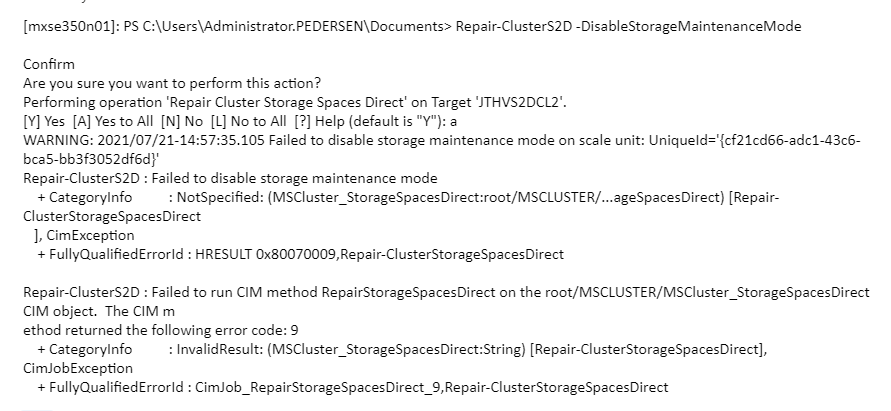
But it would throw the error Failed to disable storage maintenance mode on scale unit: UniqueId='{cf21cd66-adc1-43c6-bca5-bb3f3052df6d}’
As this is a Azure Stack HCI cluster i decided to reach out to support and opened a ticket via the Azure Portal. Within 1 hour i had a engineer on the case and we collected alot of logs, did some debuging and tried to stop maintenance mode. But that did not help.
We also tried rebooting the host with the disks that was stuck in maintenance mode but no luck
We tried resetting the disks, trying to unbind the disks from S2D and all of that. In the end nothing was working so we did a ttracer debug logging on the SMPHOST process. This did not solve anything.
A week after this we had a power outage and my UPS won’t hold the servers alive for more then 30 minutes so i had to turn them off. After booting them up again the disks where out of storage maintenance and all was good.
Conclusion
The theory is that some metadata was stored on the other node in the cluster that had not been booted. But still had it’s physicaldisks ok. So if you encounter this issue. If you have data and vm’s stop vm’s and reboot the other node if it’s a 2 node. If that does not work. Stop the cluster and shutdown all nodes, and reboot them at the same time. That sounds like it cleared up something that was stuck.
Hi Jan
I have a similar issue after installing februar update to my 4 node 2022 s2c cluster.
The first node I updated is stuck on stopping maintenance mode, so I stopped updating 🙂
just to confirm was this a cluster of 2022 windows servers ? I am not very excited to reboot the whole thing with over 50 production vm’s on it.
No this was on Azure Stack HCI 21H2 but the same things will apply to 2022 as well.
Thank you Jan
One more question, after the reboot of the cluster were you able to continue patching, without this issue resurfacing ?
Hello,
I had a similar issue when using Enable-StorageMaintenanceMode on a Node of a 2-Node-Cluster in preparation of an OS upgrade : the Node’s disks were stuck in “{Starting Maintenance Mode…..}”
I found your post and thought “Before shutting down all those VMs, lets try a refresh on the active Node, this should suffice if cached information is the problem”, and I simply did a Refresh on Storage -> Disks in Failover Manager on the active Node….
And it worked – so thanks for putting me on the right track…