In this guide i will explain what you can do to fix a failed virtualdisk in a Failover Cluster. In S2D the ReFS volume will write some metadata to the volume when it mounts it. If it can’t do this for some reason it will jump the virtualdisk from node to node until it’s tried to mount it on the last host. Then it will fail and you will get this state in the event log and the Virtual disk will be failed.
Updated April 18th 2018

If you also look in your ReFS event log you will see things like this

Now let’s run a powershell command on one of the nodes to look at the VirtualDisk

Updated section
Microsoft has changed some settings lately on what to do when a ReFS volume goes offline on a CSV. They have given us another parameter to use. Start by running these commands.
Remove-Clustersharedvolume -name "Cluster Virtual Disk (Test)" Get-ClusterResource -Name "Cluster Virtual Disk (Test)" | Set-ClusterParameter -Name diskrunchkdsk -Value 7 Get-ClusterResource -Name "Cluster Virtual Disk (Test)" | Set-ClusterParameter -Name diskrecoveryaction -Value 1 Start-clusterresource -Name "Cluster Virtual Disk (Test)" Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask
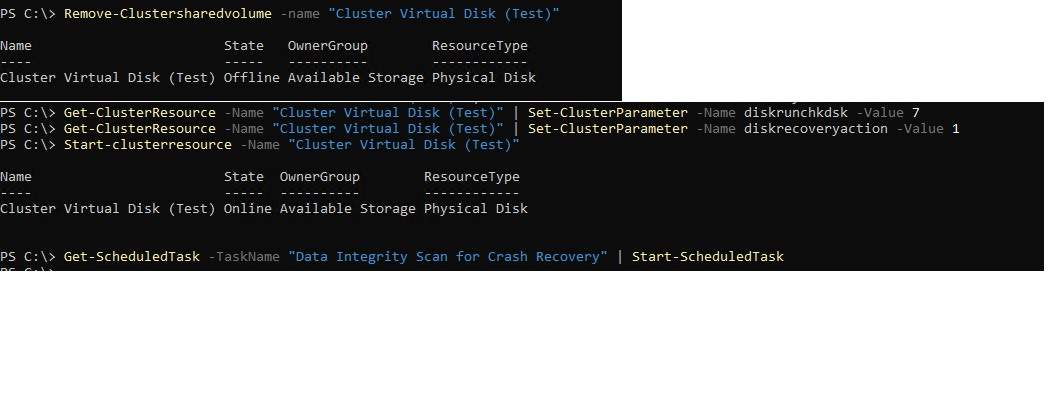
FYI the Get-ScheduledTask -TaskName “Data Integrity Scan for Crash Recovery” | Start-ScheduledTask needs to be run on the node that owns the Disk that is failed. Also run just the Get-ScheduledTask -TaskName “Data Integrity Scan for Crash Recovery” to see when it finishes. It will say running untill it’s done.
You will need to wait for the Data Integrity Scan to finish before continuing. The Integrity Scan will scan about 1 TB used space pr hour. So if you have used 8 TB it will use about 8 hours.
Now the virtualdisk should look like this in Failover Cluster manager.

Wait for any storage jobs that is running. This might happen. Run Get-StorageJob and it should be empty. Once it’s empty we can add the virtualdisk back as a Cluster Shared Volume
Stop-clusterresource -Name "Cluster Virtual Disk (Test)" Get-ClusterResource -Name "Cluster Virtual Disk (Test)" | Set-ClusterParameter -Name diskrecoveryaction -Value 0 Get-Clusterresource -Name "Cluster Virtual Disk (Test)" | set-clusterparameter -name diskrunchkdsk -value 0 Add-clustersharedvolume -Name "Cluster Virtual Disk (Test)" Start-clusterresource -Name "Cluster Virtual Disk (Test)"
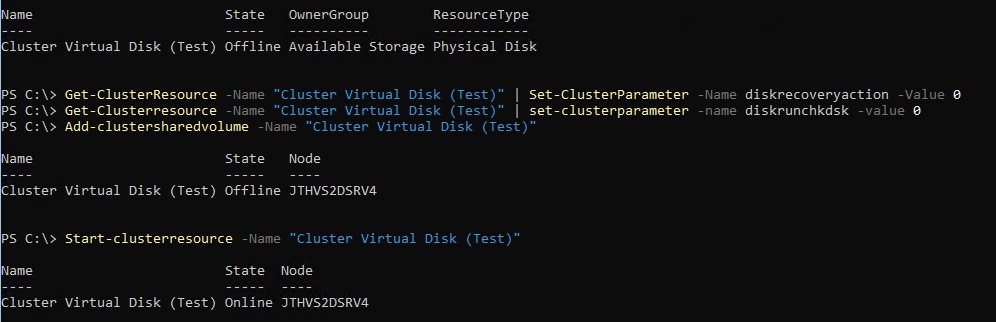
Now it should be ok. You can run
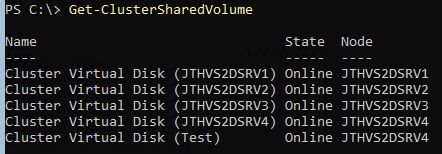
Get-ClusterSharedvolume
And it should show as online.
If the volume does not come online after starting the clusterresource. Run the first part again with the dataintegrity scan. let it sit for a while. Then do the 2nd part with commands. One time i had to do this process 10 times over before it came online.
i can confirm you can see a storagejob running after start-scheduledtask part. It will repair until its 99% complete and it moves over to a suspended state. when it reach this point execute the reverse commands and you should be good to go.
Yes, and also run the get-scheduledtask command to see if the task is still running.
Hi Jan-Tore,
A huge thank you for this fantastic article! i had 3 active passive SQL clusters unable to attached the virtual disk after a restart late on a Friday night. After hours of troubleshooting i decided to google the issue and found this page and could not have asked for more 🙂
Best regards,
NoobToClustering
Hi Jan-Tore,
also from me many thanks for this life-saving hint! It happened to us two times that we had a CSV volume in a detached state and were unable to bring it online again. After the first occurrence (during March 2018) we even opened a MS support call with no usable results. I had to finally delete/recreate the volume thereby having to accept data loss. On the second occurrence we luckily stumbled over your post here – and it helped! The recovery took about 22h in our case for a 25TB volume… Painfully long, but better than nothing.
Many regards,
Norbert
Just back online today after a recovery using this procedure.
Firstly, a huge thank you to the author who was at one stage online with me during the recovery.
And a bigger thank you to Dave Kawula a Microsoft MVP – look him up if you are ever in trouble – was insightful and helpful to the nth degree
while it was happening.
OK enough of the thank yous.
Be prepared for the step:
Get-ScheduledTask -TaskName “Data Integrity Scan for Crash Recovery” | Start-ScheduledTask
to take a *long* time with *zero* feedback about progress.
Repeatedly running Get-ScheduledTask -TaskName “Data Integrity Scan for Crash Recovery”
will result in Running… until it’s not. No feedback whatsover. You know it’s ended when it says Ready.
*Just* *wait* you have to.
YMMV but our 25TB cluster volume with 15TB of data took 16 hours to complete. I know, we should break it into smaller volumes.
Obviously different hardware configs will change this time.
But this works if you are stuck and we were online again without data loss albeit with a long(ish) downtime.
Glad to be of help, and this is the reason for sharing my findings to the rest of the world. So that others can find a solution by simply going to google or bing. Im happy all is back to normal 🙂
JT
Great Work!
I really appreciate you taking the time to share this info.
With that said, I have been struggling with this exact issue for 3 weeks. I am a small MSP and will loose clients if i don’t fix it soon.
You think you can give me a hand? I will pay for your time if need be?
If you can help, I can give you access, or just tell me what logs and screen shots you need.
Sorry for not seeing this before. Just sendt you an email.
Regards
Jan-Tore Pedersen
Good Evening sir. Hope this message finds you well. I will try not to waste too much of your time. so just two things.
1. I really enjoy your blog. I appreciate you taking the time to put this info out there.
2. I have the exact issue described in this post. I have followed these steps many times.
My S2D cluster has been down for days and as an MSP thats not good!
I am hoping you can give me an hand?
If I have to pay you a consulting fee I will good sir.
You are very knowledgeable, and I’d like to learn a few things if possible.
If you can help, let me know what you need from me , data-wise to help see whats going on. I can even arrange for you to have direct access.
works! saved me. I had multiple volumes offline and the repair job would either exception or suspend until I got the first part going for all offline drives in the pool at the same time.
When try to bring virtual disk up following your solution I still have no luck. It’s still offline. I’ve failed disks in the pool which I replaced them with brand new disks but don’t show up as available,instead I see the get-physicaldisk showing removing from pool,communication lost with old disk serial numbers even after reboot
Hello
Without getting more info i can’t help you out. If you send me your email adress i will invite you to the slack channel we use for troubleshooting S2D. https://storagespacesdirect.slack.com
How do I private message you? I’d like to join the slack…
send me a msg on twitter, jantorep
Thanks! this is the only reference I have found to this problem.
I would have wished the events were in text, not pictures – so I found this a bit late – searching for the errors using google does not pop this article, because it’s pictures I guess.
Never the less – THANKS!
At least I got a bit of my trust in the S2D back after loosing complete access to a volume with no explanation.
I did not check the storagejob’s if any was running. You can probably wait if you want to yes if a repair job is running. But it works without waiting as well.
Regards
Jan-Tore
Many thanks for this post ! Is very “simple” but is very Good !
Just before to re-add the VirtualDisk to the Cluster, It’s possible to wait the Repair Storage Job.
Best regards,
Philippe G.